

시작하기 전에
엄청난 상업적 성공(흑자는 아니지만)을 이룬 chatGPT의 기반 기술이 되는 GPT의 첫 논문이다. 참고로 GPT는 1, 2, 3이 논문으로 공개되어 있지만 개인적으로는 따로 적진 않거나 아마 묶어서 이야기 하지 않을까 싶기도 하다.
트랜스포머 리뷰를 하고 나서 어느정도 로드맵을 생각했는데 우선 트랜스포머를 각기 다른 방식으로 응용한 GPT와 BERT를 리뷰해보고, 그 다음에는 스케일과 도메인을 확장한 ViT(그리고 GPT2도 살짝..), 마지막으로는 새로운 방향인 Gemini Diffusion과 Mamba를 다룰 예정이다. 아마 Gemini Diffusion을 이야기 할 때 background로 diffusion을 다루게 될 듯?
만약 트랜스포머나, 인공지능 모델에 대한 구조적인 이해가 부족하다면 아래 글을 한번 읽고 오면 좋을 것이다. 이번 글에서는 Background 파트는 아래 글로 대체한다.
[논문리뷰] Attention Is All You Need (2017) + 트랜스포머 논문을 읽고 싶은 비전공자를 위한 설명
시작하기 전에거의 1년만에 작성하는 논문 리뷰다. 그 동안 논문을 보지 않은건 아니지만, 요즘 LLM을 사용하면서 글 쓰고 읽는 법을 잃어버린 사람이 되어버렸다. 앞으로는 스스로 작문하는 능
data2lang.tistory.com
Background
이 논문을 읽기 전에 당시의 컨텍스트를 짧게 정리하자면, Word2Vec을 통해 단어 임베딩을 활용하면 매우 효과적으로 언어 모델을 학습시킬 수 있음을 증명을 해놓았기 때문에, 컨텍스트 처리만 해결되면 문장이나 문서 전체로 해결할 수 있다는 아이디어가 제시되곤 했다. 그러나, 트랜스포머 이전엔 RNN의 구조적 한계로 문장이 길어질수록 정보의 손실이 발생하고 모델의 구조가 커질수록 필요한 연산 시간이 선형적으로 증가하는 문제가 있었다.
트랜스포머는 Multi-head attention 구조를 통해 이를 효과적으로 해결했고, 이전까지 있었던 모델 크기의 제약과 컨텍스트의 한계를 뛰어넘었다. 그러나, 트랜스포머를 활용하더라도 어텐션을 학습시키기 위한 학습 데이터가 필요했고 지도 학습 특성 상 데이터와 라벨이 동시에 필요한 상황이 되었다. 아무리 많은 정보를 학습할 수 있다 하더라도, 학습을 시키는 데 필요한 비용이 많이 들어가 결국 의미가 없는 일이 되는 문제에 직면하게 되었다.
그리고 Multi-head attention의 구조를 통해 자연어의 다양한 패턴을 학습할 수 있다는 뜻은 품사를 가르쳐준다고 해서 의미를 이해할 수 있는게 아닌 것처럼, 다양한 패턴에 대한 라벨 데이터가 필요함을 의미한다. 그럼, 지도학습을 하지 않으면 되는 것 아니야? (맞음)
참고로 트랜스포머의 등장 후 1년이 흐르고 방향성이 꽤 다른 두 논문이 등장했는데, 하나는 양방향으로 동작하는 언어 모델인 BERT, 하나는 단방향으로 동작하는 생성 모델인 GPT이다. 7년이 흐른 지금 되돌아보면, 학습 비용에 대한 부담을 깨버린 GPT의 성공은 이미 예견되지 않았을까...
핵심 아이디어
Background를 길게 쓴 이유가 여기에 있다. GPT의 핵심 아이디어가 꽤 단순해서 설명할 내용이 길지가 않다. 지도 학습을 시키기엔 많은 학습 비용이 발생하니,비지도 학습을 시켜서 언어 모델링으로 사전훈련을 한 다음, 지도 학습으로 파인튜닝해서 출력만 잘 내면 된다! 가 아이디어다.
또한 이 논문에서는 하나의 사전 훈련된 모델을 파인튜닝해서 여러 Task를 처리할 수 있도록 각 Task별 학습 방식도 제안하고 있다. 일부 Task는 같은 모델을 여러 번 사용하고 있는 모습도 볼 수 있다.
GPT-1의 구조는 생각보다 단순하게 트랜스포머의 디코더만 가져와서 12개 적층한 구조이다. 각 트랜스포머 블록은 768차원 임베딩과 12개의 어텐션 헤드를 가진다. 아래 사진을 보면서 연산 순서를 살펴보자. (총 144개의 어텐션 헤드)
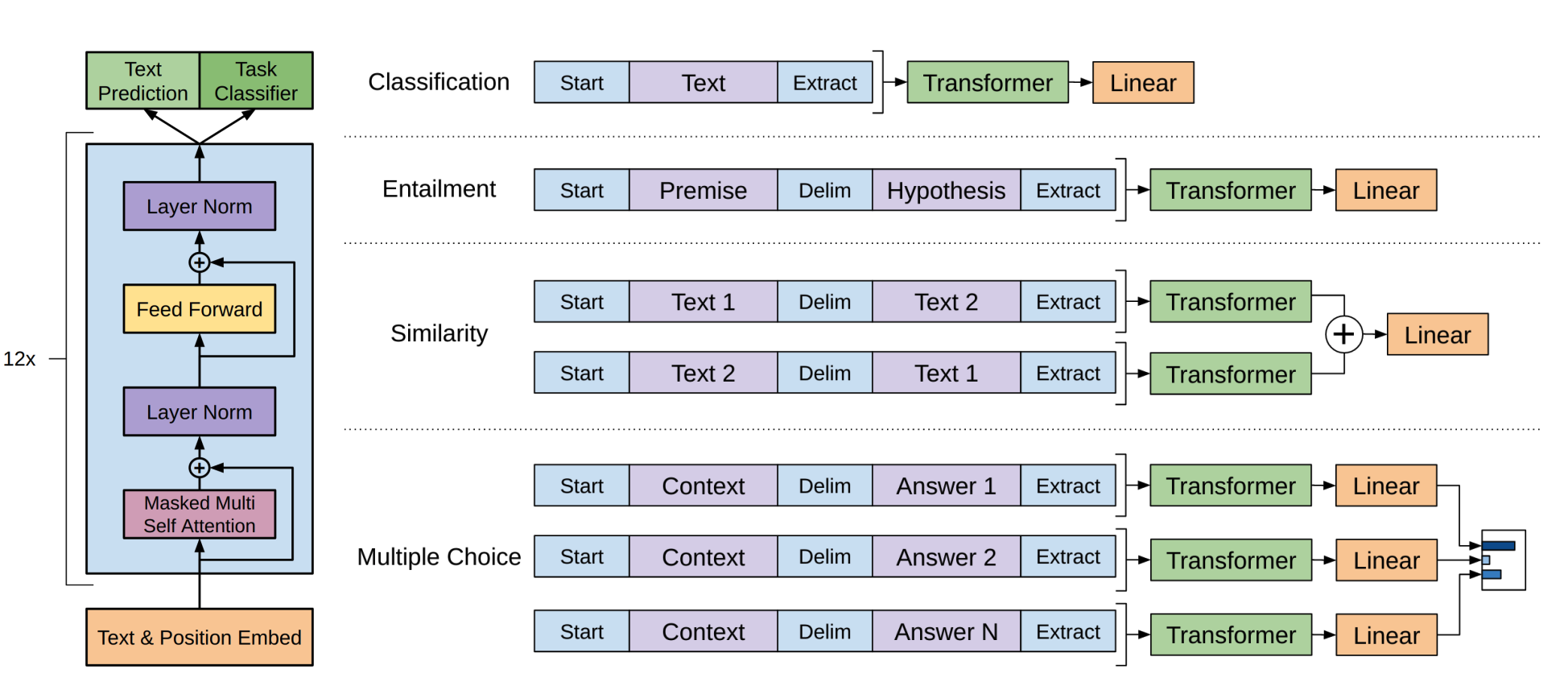
GPT-1 연산 순서
1. Text & position Embed - 트랜스포머의 디코더가 학습할 때, 임베딩 된 문자들과 그 위치까지 같이 학습한다고 설명했다. 단, Masked 된 상태로 학습하기 때문에, 이전 토큰들만 학습할 수 있다.
2. Masked Multi Self Attention - 어텐션들을 학습시킨다. Query, Key, Value 모두 같은 시퀀스에서 생성한다.
3. Residual Connection - 어텐션 연산 이후, 기존 임베딩 데이터와 잔차 연결한다. 이를 통해 정보 손실을 방지한다.
4. Layer Norm - 정규화를 거친다. (이 때는 잔차 연결 후 정규화. GPT-2부터는 Pre-Norm을 적용한다. 이 차이도 재밌다.)
5. Feed Forward - Linear(확장)>GELU>Linear(축소) 과정을 통해 표현력을 증가시킨다. (ReLU대신 GELU를 사용한 점도 재밌다.)
6. Residual Connection - 정규화 이후, Feed Forward 이전의 데이터와 잔차 연결한다. (4단계 + 5단계)
7. Layer Norm - 정규화를 거친다.
-- 여기까지 각 단계는 순차적으로 실행된다. 하지만 블록 내 토큰 처리나 블록 내 어텐션들의 학습은 병렬적으로 처리된다.
8. 12개의 트랜스포머 블록이 위 1-7 단계를 순차적으로 수행한다.
9. 12번째 블록의 출력을 선형 변환하고, 768차원을 어휘 크기인 40,000차원으로 변경한다.
10. Softmax를 통해 확률 분포 형태로 변환한다.
11. (훈련 시) 손실 계산과 역전파를 통해 학습을 진행한다.
12. (추론 시) 출력할 토큰을 선택한다. (여러가지 방식이 있는데 이건 나중에 기회가 되면 설명...)
GPT의 4개 Task별 처리 방법
- Classification: [Start] text [Extract]
- Entailment: [Start] premise [Delim] hypothesis [Extract]
- Similarity: 양방향 처리 후 합산 (순서에 의한 유사성 하락을 방지)
- Multiple Choice: 각 선택지별 독립 처리
트랜스포머의 구조를 가져와서 디코더만으로 구성해 모델 구조를 간단하게 만든 다음, 하나의 Backbone 모델 + 파인튜닝을 통해 각 Task별 활용까지 제시하고 있다. 논문의 서론에서 왜 이렇게 하는지에 대한 간단한 설명이 있는데, 이 모델의 목표는 효율적으로 광범위한 작업에 전이할 수 있는 범용적인 표현을 학습하는 것이기 때문이다.
위에서 언급했듯이 GPT-1에서는 ReLU 대신 GELU (Gaussian Error Linear Unit)를 사용했다. 이게 당시에는 꽤 신선한 선택이었는데, ReLU가 0 이하의 값을 완전히 죽여버리는 반면 GELU는 좀 더 부드럽게 처리한다. 핵심은 입력값이 음수여도 완전히 0이 되지 않고 작은 값이라도 살려둔다는 거다.
이게 특히 자연어 처리에선 미묘한 어투와 같은 정보를 살리는 데 유효했던 것 같다. 현대에도 대부분의 트랜스포머 기반 모델들이 GELU를 사용하는 것을 보면 선구안이 있었을지도... 특히 GPT-1 실험 결과는 당시 SOTA 수준을 뛰어넘었고, 범용 모델 만들 수 있고 + 비지도 학습으로도 이렇게 좋은 성능을 낼 수 있다는 인식을 심어준 계기가 되었다고 볼 수 있다.
"지도 학습은 비싸니 비지도 학습으로 사전훈련하고, 파인튜닝 하자" 라는 간단한 아이디어를 이렇게까지... 다음은 원래 BERT를 리뷰하려 했는데, 구글 선생님들께서 이번 제미나이 리포트를 오픈해주셔서 리뷰할 예정이다. 뭔가 트랜스포머에 비해 분량이 짧게 느껴진다면, 트랜스포머는 아키텍처적 혁신이고 GPT는 그 아키텍처를 어떻게 활용할지에 대한 혁신이라 그렇다고 볼 수 있다. (아님말고~)
- 추가 -
제미나이 리포트라고 해서 봤는데 내가 기대했던 Gemini Diffusion에 대한 내용은 아니었다... ㅠㅠ 이미 알려져 있는 기술들을 어떻게 잘 조합했는지 정도인 것 같다. (아직 다 읽지는 않았음)